CUDA-ийн үндсэн ойлголт ба архитектур
CUDA (Compute Unified Device Architecture) нь NVIDIA-аас боловсруулсан параллель тооцооллын платформ бөгөөд GPU-ийн өндөр зэрэгцээ (parallel) архитектурыг ерөнхий зориулалтын тооцоололд ашиглах боломжийг бүрдүүлдэг. Уламжлалт CPU-д суурилсан тооцоолол нь цөөн тооны хүчирхэг цөм дээр дараалсан гүйцэтгэлд төвлөрдөг бол CUDA нь олон мянган хөнгөн жинтэй thread-үүдийг зэрэг ажиллуулж, data-parallel шинж чанартай бодлогуудыг илүү үр ашигтай шийдвэрлэх боломжийг олгодог. Энэ архитектурын ялгаа нь их хэмжээний өгөгдөл дээр давтагдах ижил төрлийн үйлдлүүдийг гүйцэтгэх шаардлагатай орчинд GPU-г илүү тохиромжтой болгодог бөгөөд ингэснээр өндөр гүйцэтгэл, throughput-д суурилсан тооцооллыг хэрэгжүүлэх нөхцөлийг бүрдүүлдэг.

CUDA програмчлалын загвар ба гүйцэтгэл
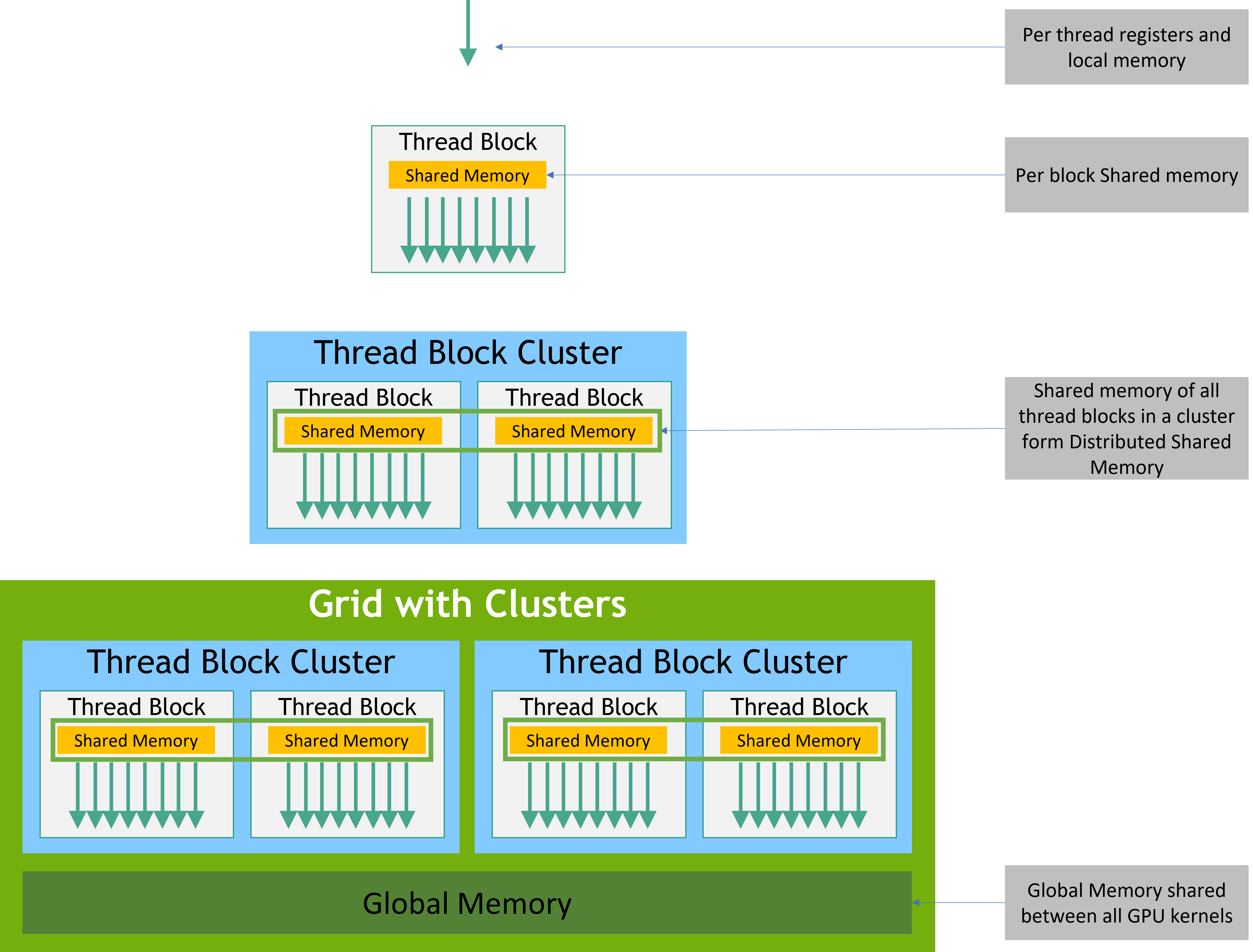
CUDA-ийн програмчлалын загвар нь host-device хэмээх хосолмол бүтэц дээр тулгуурладаг бөгөөд CPU нь удирдлага, санах ойн зохицуулалтыг хариуцаж, GPU нь тооцооллын үндсэн ачааллыг гүйцэтгэдэг. CUDA C/C++ болон бусад хэлний өргөтгөлүүдээр дамжуулан бичигдэх kernel функцууд нь GPU дээр гүйцэтгэгдэж, эдгээр kernel-ууд нь thread, block, grid гэсэн шаталсан зохион байгуулалттайгаар ажилладаг. Thread-үүд нь SIMD төстэй загвараар ижил кодыг өөр өөр өгөгдөл дээр гүйцэтгэх бөгөөд shared memory, global memory зэрэг олон түвшний санах ойн бүтэц ашиглан өгөгдлийн хандалтын саатлыг багасгах боломжтой. Гүйцэтгэлийг оновчлохын тулд memory coalescing, occupancy, warp scheduling зэрэг ойлголтууд чухал үүрэг гүйцэтгэдэг бөгөөд эдгээрийг зөв ашиглах нь CUDA програмын бодит хурдыг тодорхойлдог.
CUDA-ийн хэрэглээ ба бодит хэрэглээний орчин
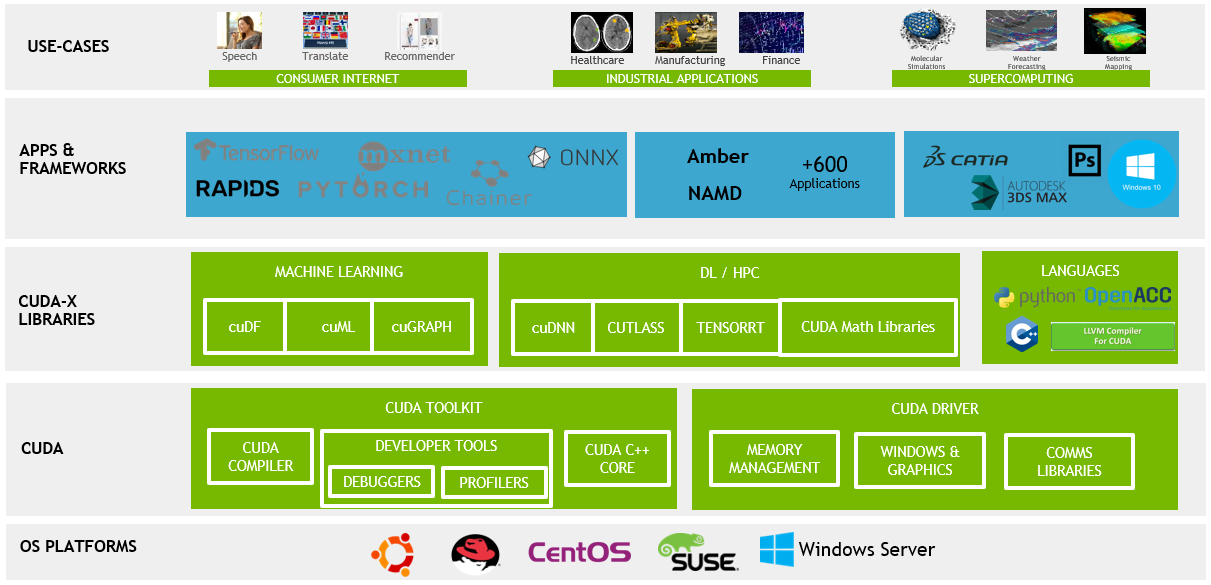
Практик хэрэглээний хувьд CUDA нь өндөр гүйцэтгэл шаардсан олон салбарт стандарт шийдэл болон хөгжсөн. Ялангуяа machine learning болон deep learning-ийн хүрээнд TensorFlow, PyTorch зэрэг framework-ууд CUDA-г ашиглан tensor тооцооллыг хурдасгаж, том хэмжээний нейрон сүлжээг богино хугацаанд сургах боломжийг бүрдүүлдэг. Үүнээс гадна scientific computing, computational physics, bioinformatics, image болон signal processing зэрэг салбаруудад матрицын үйлдэл, дифференциал тэгшитгэл, симуляци зэрэг өндөр давтамжтай тооцооллыг GPU дээр шилжүүлснээр гүйцэтгэлийг мэдэгдэхүйц нэмэгдүүлдэг. Мөн real-time rendering, autonomous systems, financial modeling зэрэг бодит цагийн болон latency мэдрэмтгий хэрэглээнүүдэд CUDA нь өргөн хэрэглэгддэг.
Давуу тал, хязгаарлалт ба инженерчлэлийн сорилтууд
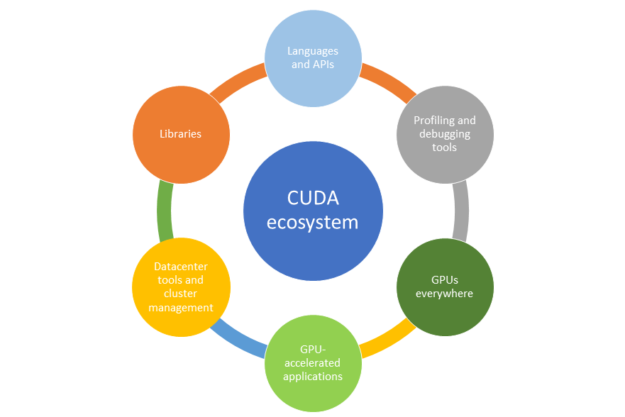
Гэсэн хэдий ч CUDA-г үр ашигтай ашиглах нь зөвхөн parallel hardware ашиглахтай хязгаарлагдахгүй бөгөөд алгоритмын бүтэц, өгөгдлийн хуваарилалт, санах ойн менежмент зэрэг олон хүчин зүйлсийг нарийн төлөвлөх шаардлагатай. Data transfer latency (CPU-GPU хооронд), synchronization overhead, мөн thread divergence зэрэг нь гүйцэтгэлд сөргөөр нөлөөлөх боломжтой. Түүнчлэн CUDA нь NVIDIA-ийн экосистемд хамааралтай тул hardware dependency үүсгэдэг нь portability-ийн хувьд сул тал болж болно. Иймээс CUDA-г ашиглахдаа асуудлын шинж чанарыг зөв тодорхойлж, parallelization хийх боломжтой эсэхийг үнэлэх нь чухал бөгөөд зөв хэрэгжүүлсэн тохиолдолд энэ технологи нь уламжлалт CPU-based шийдлүүдээс хэд дахин илүү гүйцэтгэл үзүүлэх боломжтой юм.