
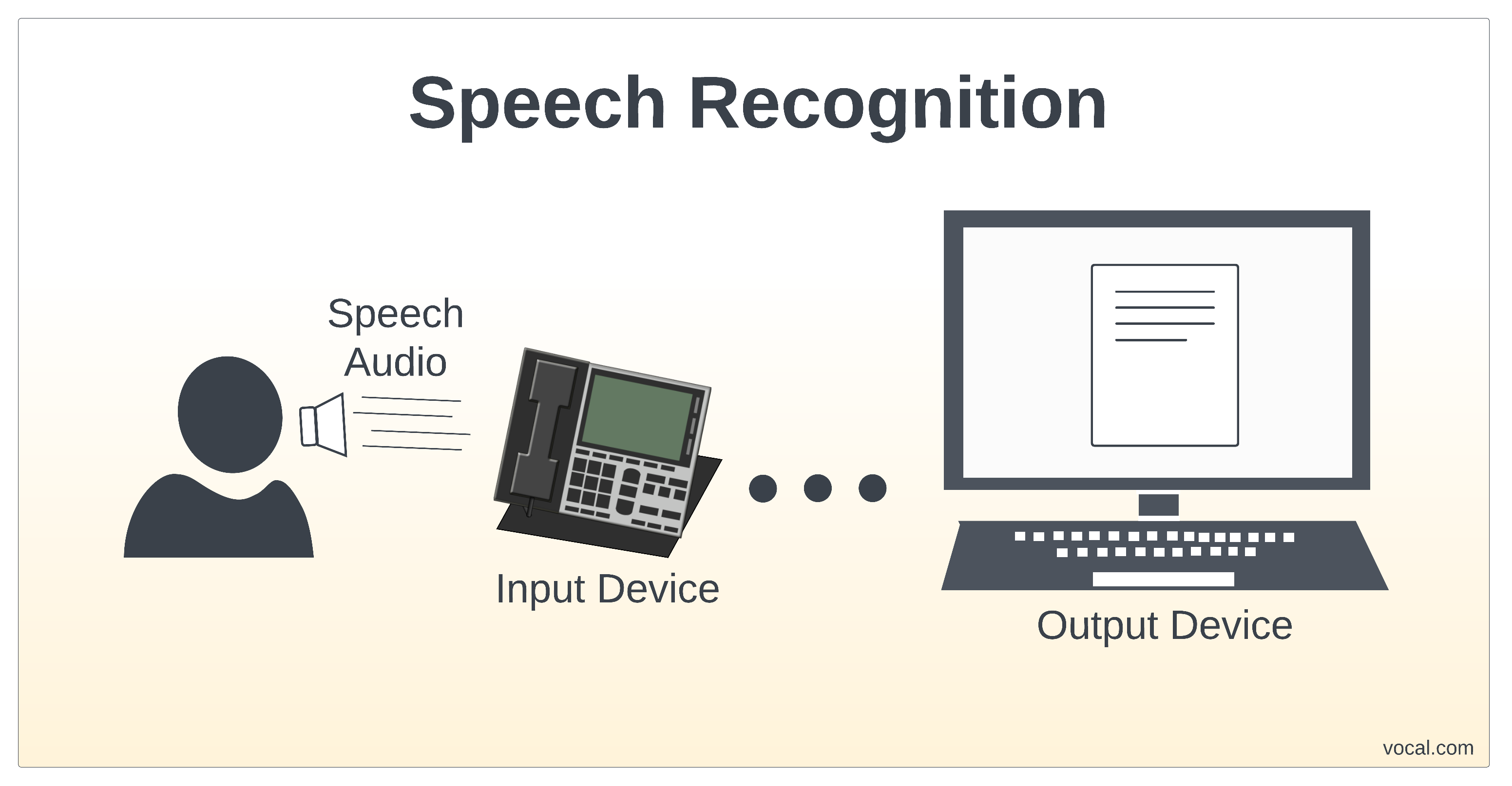
Орчин үеийн мэдээллийн технологийн хөгжлийн үр дүнд хүн ба компьютерын харилцаанд томоохон тэсрэлт гарсан нь Хэл яриаг автоматаар таних технологи (Automatic Speech Recognition – ASR) юм. Энэхүү технологи нь хүний хэлсэн үгийг дижитал текст хэлбэрт хөрвүүлэх замаар бидний амьдралыг хөнгөвчилж байна.
Хэл яриаг текст болгон хувиргах үндсэн үе шатууд
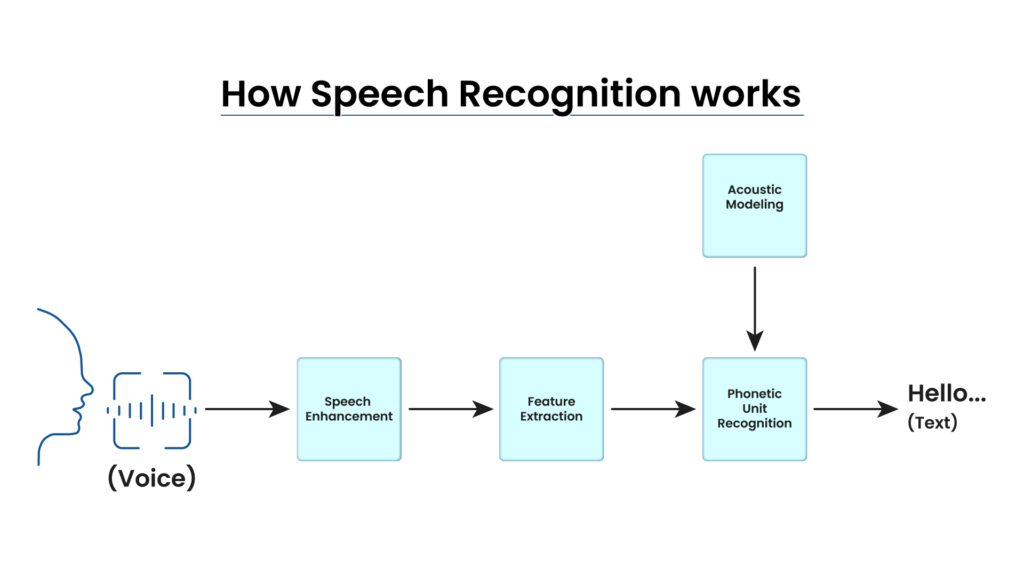
Хэл яриаг таних процесс нь физик долгионыг утга бүхий дижитал мэдээлэл болгон хувиргах нарийн төвөгтэй алгоритмуудын дараалал юм. Энэхүү үйл явцыг дараах үндсэн гурван үе шатанд хуваан авч үздэг.
1. Дохио боловсруулах ба шинж чанар ялгах үе шат
Хүний яриа нь агаараар дамжих физик долгион буюу аналог дохио юм. Компьютер энэ долгионыг шууд боловсруулах боломжгүй тул микрофоноор дамжуулан хүлээн авч, дижитал хэлбэрт шилжүүлдэг.
- Хувиргах процесс: Дууны долгионыг маш бага хугацааны (миллисекунд) интервалтайгаар жижиг хэсгүүдэд хуваан, давтамжийн шинжилгээ хийдэг.
- Үр дүн: Энэхүү процессоор дууны сигналаас хүний хоолойны өнгө, авианы онцлогийг илэрхийлэх математик векторууд буюу компьютерт зориулсан “дууны зураглал”-ыг гарган авдаг.
2. Дуу авианы(Acoustic Model) загварчлал: Авиаг таних үе шат
Энэ шатанд систем өөрт байгаа асар их хэмжээний сургалтын өгөгдөл (Big Data) дээр үндэслэн дижитал зураглалыг авиатай дүйцүүлдэг.
- Хувиргах процесс: Систем “С”, “А”, “Й”, “Н” гэх мэт тусдаа авианууд ямар давтамжийн үзүүлэлттэй байдгийг аудио материалтай харьцуулан шинжилдэг.
- Үр дүн: Дууны зураглалыг хэл шинжлэлийн хамгийн бага нэгж болох авиа болгон хөрвүүлнэ.
3. Хэлний загварчлал
Зөвхөн авиаг таних нь хангалтгүй бөгөөд утга зүйн логик алдаанаас сэргийлэх шаардлагатай. Учир нь хүний ярианд ижил сонсогдох боловч өөр утгатай үгс олон тохиолддог.
- Хувиргах процесс: Хэлний загвар нь үгсийн дарааллын магадлалыг тооцоолж, өгүүлбэрийн ерөнхий контекстийг шинжилнэ. Жишээ нь, “Би утсаар ярив” гэх өгүүлбэрт “хар” (өнгө) биш “гар” (эрхтэн) гэдэг үг орох нь логикийн хувьд илүү магадлалтайг тогтоодог.
- Үр дүн: Авианы цуглуулгыг хэл зүйн хувьд зөв, утга бүхий бүрэн хэмжээний бичвэр (текст) болгон эцсийн хэлбэрт оруулна.
4. Орчин үеийн шийдэл: Хиймэл оюун ухаан
Сүүлийн жилүүдэд Гүн сургалт (Deep Learning) болон Хиймэл мэдрэлийн сүлжээ (Neural Networks)-ний тусламжтайгаар ASR системүүд хүний тархины мэдээлэл боловсруулах зарчмаар ажиллах болсон. Өмнө нь авианы загвар болон хэлний дүрмийг тус тусад нь сургадаг байсан бол орчин үеийн End-to-End архитектур нь асар их хэмжээний өгөгдөл дээр шууд “сонсож” суралцдаг болсон. Ингэснээр систем дуу хоолой болон текстийн хоорондох шууд хамаарлыг өөрөө тогтоож, хэл шинжлэлийн нарийн төвөгтэй дүрмүүдийг контекст дотор нь илүү оновчтой тооцоолох боломжтой болсон. Энэ нь таних үйл явц дахь алдааны хувийг эрс бууруулж, хүний яриаг бодит цаг хугацаанд нарийвчлалтай хөрвүүлэх гол хөшүүрэг болж байна.

5. Системийн нарийвчлалд нөлөөлөх гол сорилтууд
Хэл яриаг таних технологийн нарийвчлал болон найдвартай ажиллагаанд дараах хүчин зүйлс гол саад болдог:
Бие физиологийн өөрчлөлт: Ханиад хүрэх эсвэл хоолой өвдөх үед хүний дууны хөвчний хэлбэлзэл болон амны хөндийн резонанс өөрчлөгддөг. Энэхүү өөрчлөлт нь Дуу авианы загварт (Acoustic Model) алдаа үүсгэж, систем тухайн хүний дуу хоолойг буруу таних эсвэл нарийвчлал эрс буурахад хүргэдэг.
Аялга ба хурд: Хэрэглэгч бүрийн ярианы өвөрмөц хэмнэл, нутгийн аялга болон дуудлагын онцлог нь системд тодорхойгүй байдал үүсгэдэг.
Орчны шуугиан: Салхи, шуурга болон бусад гадаад орчны чимээ нь үндсэн аудио дохиотой давхцан “дууны бохирдол” үүсгэдэг. Ингэснээр систем хүний яриаг хөндлөнгийн чимээнээс ялгаж салгахад хүндрэлтэй болдог.


