
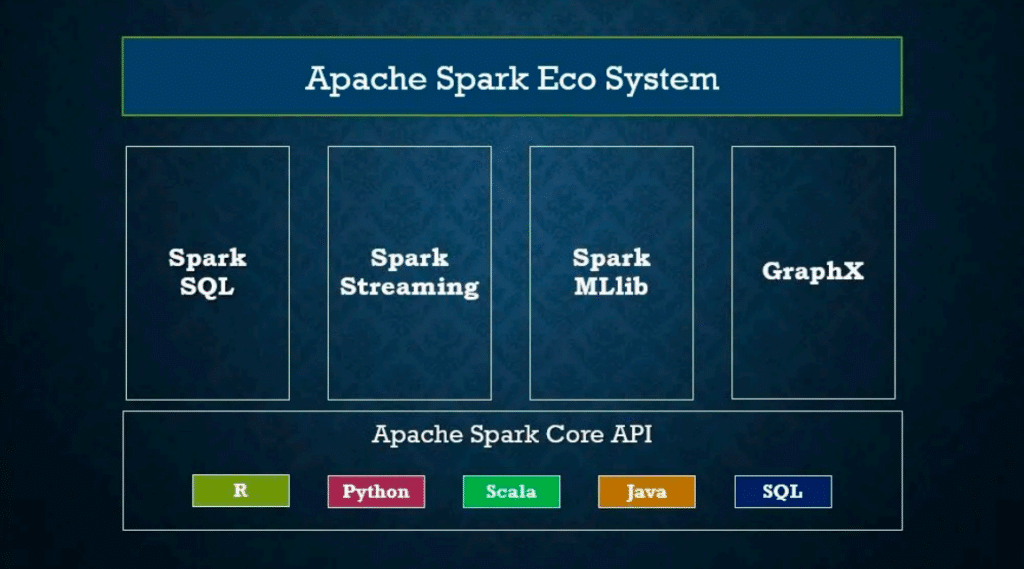
Spark SQL нь SQL болон DataFrame API-г хангаснаар Apache Spark-ийн бүтэцлэгдсэн өгөгдөлтэй ажиллах үйл явцыг хялбаршуулж, хэрэглэгчдэд танил интерфейс болон хэрэгслүүдийг ашиглан өгөгдөл боловсруулах, дүн шинжилгээ хийх, хүсэлт(querying ) хийх боломжийг олгодог. Энэ нь төрөл бүрийн өгөгдөл боловсруулах, аналитик ажлуудад зориулсан Apache Spark экосистемийн чухал бүрэлдэхүүн хэсэг болсон.
Spark SQL нь дараах гол онцлогуудтай:
^SQL дэмжлэг: Spark SQL нь өгөгдлийн янз бүрийн формат, тухайлбал JSON, Parquet, Hive хүснэгтүүд зэрэгт хадгалагдсан өгөгдөлд уугуул SQL асуулга ажиллуулах боломжийг олгодог.
^DataFrame API: DataFrame-үүд нь өгөгдлийн эх үүсвэрээс үүсгэгдэж болох ба өндөр түвшний API-г ашиглан өгөгдөлд хувиргалт, нэгтгэл, нэгдэл зэрэг үйлдлүүдийг хийх боломжтой.
^Гүйцэтгэлийн оновчлол: Spark SQL нь Catalyst гэх өөрийн гүйцэтгэлийн оновчлогчийг ашигладаг. Энэ нь SQL асуулгуудад янз бүрийн оновчлол хийх боломж олгодог.
Spark MLlib (Machine Learning Library) их хэмжээний өгөгдөлд дүн шинжилгээ хийх, загварчлах даалгавруудыг хялбархан шийдвэрлэх боломжийг хэрэглэгчдэд олгодог, өргөтгөх боломжтой, түгээсэн машин сургалтын программуудыг бий болгох хүчирхэг хэрэгсэл юм. Энэ нь их өгөгдлийн технологийг машин суралцах, урьдчилан таамаглах аналитик хийхэд ашиглахыг эрэлхийлж буй байгууллагуудын түгээмэл сонголт болсон.
Spark MLlib нь дараах гол онцлогуудтай:
^Өргөжих боломж: Spark-ын тархсан тооцооллын архитектурыг ашиглан тооцооллыг параллелизаци хийж, кластер дахь машинуудаар өгөгдлийг үр дүнтэй боловсруулдаг.
^MLlib нь ангилал, регресс, кластерчлал, хамтын шүүлт, хэмжээсийг бууруулах зэрэг олон төрлийн машин сургалтын алгоритмуудыг агуулдаг.
^Гүйцэтгэлийн оновчлол: MLlib нь тархсан өгөгдлийн бүтэц (RDD, DataFrame гэх мэт), санах ойд кешлэх, параллель тооцоолол зэрэг оновчлолуудыг ашигладаг. Мөн загварын оршин байх, сериалчлалыг дэмждэг тул сургасан загваруудыг хадгалах, дахин ашиглах боломжтой.

Spark GraphX том хэмжээний график бүтэцтэй өгөгдөл дээр график аналитик хийх, олборлох хүчирхэг хэрэгсэл юм. Энэ нь график тооцоолол, алгоритмыг илэрхийлэх нэгдсэн тогтолцоог бий болгож, хэрэглэгчдэд тархсан орчинд график дээр суурилсан нарийн төвөгтэй асуудлуудыг шийдвэрлэхэд хялбар болгодог.
Spark GraphX нь дараах гол онцлогуудтай:
^Графын дүрслэл: GraphX нь тархсан графын абстракцыг санал болгодог бөгөөд энэ нь оройнууд (vertices) ба ирмэгүүд (edges)-ийн цуглуулга хэлбэрээр графыг дүрсэлдэг. Энэ нь кластер дахь машинуудад тархсан байдлаар том хэмжээний графуудыг үр дүнтэй байдлаар бий болгох, удирдах боломж олгодог.
^Графын үйлдлүүд ба алгоритмууд: GraphX нь өргөн хүрээний графын үйлдлүүд ба алгоритмуудыг санал болгодог, үүнд:
Орой ба ирмэгийн хувиргалтууд: map, join, filter
Графын агрегатууд ба группчилал: aggregateMessages, groupEdges
Графын алгоритмууд: PageRank, Connected Components, Triangle Counting
Графын асуулга ба хэв маягийн тааруулалт: subgraph, connectedComponents.
Гүйцэтгэлийн оновчлол: GraphX нь Spark-ын тархсан тооцооллын хөдөлгүүрийг ашиглан графын тооцооллыг параллелизаци хийдэг. Энэ нь том хэмжээний графуудыг үр дүнтэй боловсруулах боломжийг олгодог. Мөн орой-хуваарилах стратегиуд, мессеж дамжуулах оновчлол зэрэг графын тодорхой үйлдлүүдэд зориулсан оновчлолуудыг хэрэгжүүлдэг.
Spark Streaming бодит цагийн өгөгдөл боловсруулах, аналитик программуудыг бий болгох хүчирхэг хэрэгсэл бөгөөд хэрэглэгчдэд өгөгдлийн урсгалыг бага хоцролттой, өндөр дамжуулалттай, алдааг тэсвэрлэх чадвартай боловсруулж, шинжлэх боломжийг олгодог. Энэ нь бодит цагийн хяналт, залилан илрүүлэх, зөвлөмж өгөх систем гэх мэт янз бүрийн салбарын байгууллагуудад түгээмэл сонголт болсон.
Хайлт
Категори
- 1 минутын уншлага
- 2 минутын уншлага
- AI
- Algorithm
- Bиртуалчлал
- Competitive programming
- computer science
- ide
- webiste
- Аюулгүй Байдал (4)
- боловсрол
- Зөвлөгөө
- Инженерчлэл ба Технологийн Системүүд (2)
- Код
- Компьютерын Шинжлэх Ухаан ба Програмчлал (1)
- Крипто
- Математик
- Өгөгдөл ба Хиймэл Оюун Ухаан (3)
- Программ хангамжийн төсөл
- Систем
- Сурагчдад
- Тархи ба Код
- Технологи, Нийгэм ба Боловсрол (5)
- Технологийн түүх
- Тоглоом хөгжүүлэлт
- Хөндлөнгийн
- Электроник


