
Эх хэл боловсруулалт нь ойрын хугацаанд эрчээ аваад байгаа бөгөөд Chatgpt, Deepseek, Gemini зэрэг моделиуд нь дэлхий даяар олон сая хүмүүсийн өдөр тутмын хэрэглээнд нэвтрээд байгаа билээ. Хүний ярьдаг хэлийг компьютер ойлгох боломжтой болгож өгсөн хэд хэдэн чухал техник байдгаас өнөөдөр би хамгийн суурь ойлголт буюу үг токенчлох үйл явцыг онцлон өгүүлмээр санагдлаа.

Токен гэж юу вэ?
Эх хэлний моделиудын ард маш их өгөгдөл байдаг. Ихэнх хэлний моделиуд web scraping (Веб сайтуудаас хэрэгтэй текстийг ялгаж авах техник ) ашиглаж интернэтийн сая сая сайтуудаас өгөгдлөө цуглуулж бэлтгэдэг. Тухайн цуглуулсан өгөгдлүүдээсээ Vocabulary List (Үгийн сан) байгуулдаг. Энэхүү их хэмжээний өгөгдлийг боловсруулахад ямар нэгэн байдлаар хэсэгчлэн хуваах хэрэгтэй нь ойлгомжтой юм. Ингэхдээ үг үсгээр нь салган задалдаггүй харин токен гэх нэгжээр задлан бүхий л текстийг энэхүү нэгжээр хэмждэг.
Яагаад үсэг үсгээр нь биш гэж? Үсэг үсгээр нь хувааж боловсруулалт хийж болох ч энэ нь маш их хүчин чадал бөгөөд нөөц шаардана.
Яагаад үг үгээр нь биш гэж? Хэрвээ үг үгээр нь хуваавал адилхан язгууртай үгнүүд тусдаа өөр өөр токентой болно. Жишээ нь “cурагчид” болон “cуралцагчид” адилхан утгатай үг боловч үгээр нь салгавал энэ нь өөр дугаарлалтаар хадгалагдах юм.
Жишээ болгон Chatgpt моделийн токенжуулагчыг ашиглан “Технологийн боловсролыг багаас нь олгох нь танай хүүхдийн ирээдүйд тустай. Боловсролыг инженерчлэв.” гэх өгүүлбэрийг токенжуулсан байдлыг харгалзах ID хамт харуулав.


Тухайн текстийг орчуулан Англи хэл дээр токенжуулав.

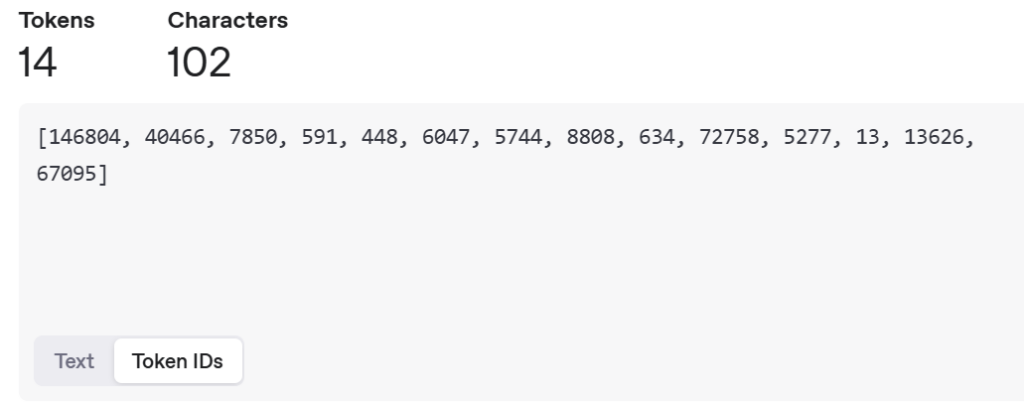
Магадгүй та хэрхэн дээрх тоонууд гараад ирснийг гайхаж байгаа байх. Хэрвээ Token ID-г сайн ажиглаад харвал хамгийн түгээмэл хэрэглэгддэг үг болон хэлцүүд бага тоогоор илэрхийлэгдсэн байгаа. Үүний учир нь токенжуулалтын аргадаа байдаг. Доор тухайн алгоритм хэрхэн ажилладаг талаар дэлгэрэнгүй харуулна.
https://platform.openai.com/tokenizer
Byte Pair encoding
Энэхүү токенуудыг алгоритм ашиглан тооцоолон гаргаж ирдэг. Ихэнх хэлний моделиуд токенжуулалт хийхдээ Byte Pair Encoding гэх алгоритмыг ашигладаг. Угтаа энэхүү алгоритм нь 1994 онд онд текстийн хэмжээг шахаж (compression) зориулалттай зохиогдсон алгоритм юм. Хамгийн анх Bert хэлний модел энэхүү аргыг эх хэл боловсруулалтад ашиглаж эхэлсэн байдаг.
Энэхүү алгоритм нь хамгийн их давтагдаж буй хэсгүүдийг нэгтгэн нэг хэсэг болгох зарчмаар ажилладаг. Мянга хэлэхээр нэг харуул гэдэгчлэн жишээгээр хэрхэн ажилладагыг харуулъя.
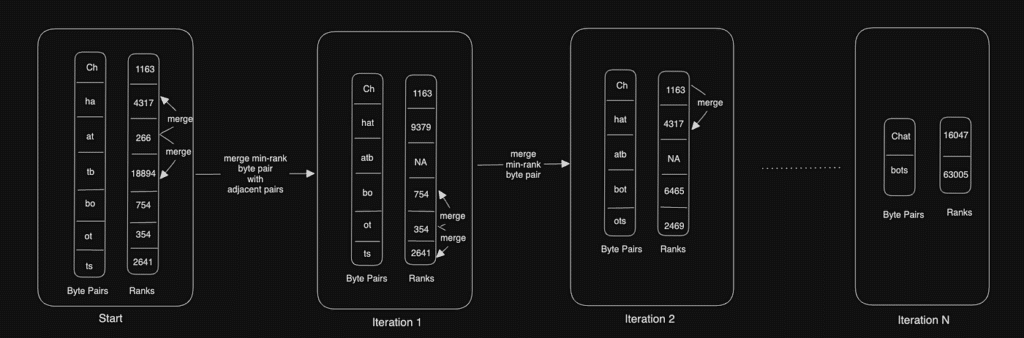
1. Үгийг тэмдэгтүүд болгон задлах
[‘T’, ‘h’, ‘e’, ‘‘, ‘e’, ‘s’, ‘s’, ‘e’, ‘n’, ‘t’, ‘i’, ‘a’, ‘l’, ‘‘, ‘e’, ‘n’, ‘g’, ‘i’, ‘n’, ‘e’, ‘e’, ‘r’, ‘i’, ‘n’, ‘g’, ‘_’, ‘e’, ‘d’, ‘u’, ‘c’, ‘a’, ‘t’, ‘i’, ‘o’, ‘n’]
2. Давтагдсан тэмдэгтийн хосуудыг тооцоолох
Дараах тэмдэгтийн хосууд хамгийн олон удаа давтагдаж байгааг харцгаая:
- _
e– 3 удаа en– 2 удааin– 2 удааng– 2 удааti– 2 удаа
3. Давтагдсан хосуудыг нэг тэмдэгт болгон нэгтгэх
[‘T’, ‘h’, ‘e ‘_e’, ‘s’, ‘s’, ‘en’, ‘ti’, ‘a’, ‘l’, ‘ ‘, ‘_eng’, ‘in’, ‘e’, ‘e’, ‘r’, ‘ing ‘, ‘_e’, ‘d’, ‘u’, ‘c’, ‘a’, ‘ti’, ‘o’, ‘n’, ‘.’]
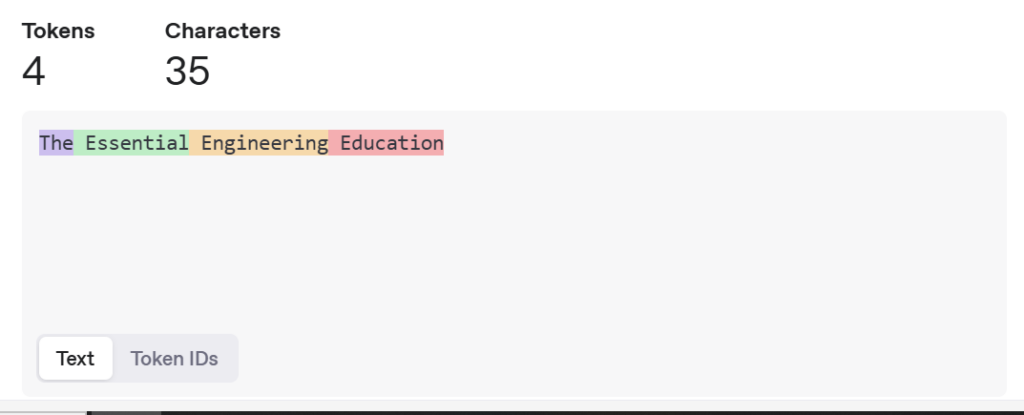
Түүнчлэн тухайн өгүүлбэрийн Chatgpt токеныг авч үзье.
Дүгнэлт
Монгол хэл дээрх текстийн токеныг англи хэлнийхтэй харьцуулахад илүү олон хуваагдсан байгааг мэргэн уншигч та олж харсан байх гэж найдаж байна. Яг адилхан моделийг өөр өөр улсын хэлний өгөгдөл дээр сургахад Монгол хэл бусад хэлнүүдээс гүйцэтгэл болон утга зүйн хувьд арай сул байгаа нь ажиглагддаг. Үүний учрыг Монгол хэлний төвөгтэй олон нөхцөлт хувиргалтууд нь токенжуулалтын үр дүнд нөлөөлсөн байж магадгүй гэж би хувьдаа таамаглаж байна.
Tokenizers-ийн талаар доорх бичлэгээс илүү ихийг олж мэдээрэй.
Эх сурвалжууд
https://www.geeksforgeeks.org/byte-pair-encoding-bpe-in-nlp
https://platform.openai.com/tokenizer
https://www.grammarly.com/blog/ai/what-is-tokenization


