Бид sklearn library болон түүнийг хэрхэн машин сургалтын алгоритмыг хэрэгжүүлэхэд ашиглах талаар суралцах болно. Бодит ертөнцөд бид үүнийг ашиглах шаардлагатай болгонд хэцүү алгоритмыг бий болгохыг хүсдэггүй. Хэдийгээр алгоритмыг анхнаасаа бий болгох нь түүний үйл ажиллагааны үндсэн ойлголтыг ойлгох гайхалтай арга боловч бид шаардлагатай үр ашиг, найдвартай байдалд хүрч чадахгүй байж магадгүй юм.
Scikit-learn нэртэй Python модуль нь хяналттай болон хяналтгүй сургалтын төрөл бүрийн арга техникийг санал болгодог. Энэ нь NumPy, Pandas, Matplotlib зэрэг таны мэддэг хэд хэдэн технологид суурилсан болно.
Sklearn гэж юу вэ?
Францын судлаач эрдэмтэн Дэвид Курнапогийн scikits.learn нь Google-ийн Summer of Code компани бөгөөд scikit-learn төсөл анх хэрэгжиж эхэлсэн юм. Энэ нэр нь SciPy-ийн “SciKit” (SciPy Toolkit) нэртэй өөрчилсөн гэсэн санааг илэрхийлдэг бөгөөд үүнийг бие даан бүтээж, хэвлүүлсэн. Хожим нь бусад програмистууд үндсэн кодын санг дахин бичсэн.
Францын Роккенкурт дахь Компьютерийн шинжлэх ухаан, автоматжуулалтын судалгааны Францын хүрээлэн нь 2010 онд Александр Грамфорт, Гаэл Варокуа, Винсент Мишель, Фабиан Педрегоса нарын удирдлаган дор уг ажлыг удирдан явуулсан. Тухайн жилийн 2-р сарын 1-нд тус байгууллага төслийн анхны албан ёсны хувилбарыг гаргасан. 2012 оны 11-р сард scikit-learn болон scikit-image-ийг “сайн арчилгаатай, алдартай” скикитуудын жишээ болгон дурдсан. GitHub дээр хамгийн өргөн хэрэглэгддэг машин сургалтын багцуудын нэг бол Python-ийн scikit-learn юм.
Машин сургалтын алгоритмыг хэрэгжүүлэхэд Scikit-Learn-ийг ашиглахын ашиг тус
Та ML-ийн тоймыг хайж байгаа эсэх, хурдан хурдтай болох эсвэл ML сурах хамгийн сүүлийн хэрэгслийг хайж байгаа эсэхээс үл хамааран scikit-learn нь сайн баримтжуулсан бөгөөд ойлгоход хялбар гэдгийг олж мэдэх болно. Энэхүү өндөр түвшний багаж хэрэгслийн тусламжтайгаар та урьдчилан таамагласан өгөгдлийн шинжилгээний загварыг хурдан бүтээж, цуглуулсан өгөгдөлд нийцүүлэн ашиглах боломжтой. Энэ нь дасан зохицох чадвартай бөгөөд бусад Python номын сангуудтай зэрэгцэн сайн ажилладаг.

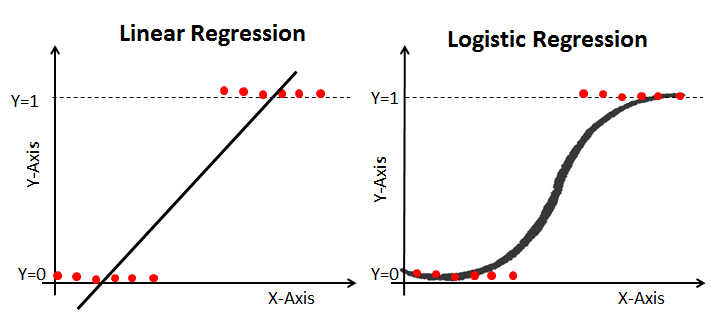
Шугаман регрессийн алгоритмын жишээ
- # Python program to show how to use sklearn to perform linear regression
- # Importing the required modules and classes
- import numpy as np
- from sklearn.model_selection import train_test_split
- from sklearn.linear_model import LinearRegression
- from sklearn.datasets import load_iris
- # Loading our load_iris dataset
- X, Y = load_iris( return_X_y=True )
- # Printing the shape of the complete dataset
- print(X.shape)
- # Splitting the dataset into the training and validating datasets
- X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.4, random_state = 10)
- # Printing the shape of training and validation data
- print(X_train.shape, Y_train.shape)
- print(X_test.shape, Y_test.shape)
- # Training the model using the training dataset
- lreg = LinearRegression()
- lreg.fit(X_train, Y_train)
- # Printing the Coefficients of the linear Regression model
- print(“Coefficients of each feature: “, lreg.coef_)
- # Printing the accuracy score of the trained model
- score = lreg.score(X_test, Y_test)
- print(“Accuracy Score: “, score)
Логистик регрессийн алгоритмын жишээ
- # Python code to see how to perform Logistic Regression using sklearn.linear_model
- # Importing the required modules and classes
- from sklearn.datasets import load_iris
- from sklearn.metrics import accuracy_score
- from sklearn.linear_model import LogisticRegression
- from sklearn.model_selection import train_test_split
- # Loading our dataset
- data = load_iris()
- # Splitting the independent and dependent variables
- X = data.data
- Y = data.target
- print(“The size of the complete dataset is: “, len(X))
- # Creating an instance of the LogisticRegression class for implementing logistic regression
- log_reg = LogisticRegression()
- # Segregating the training and testing dataset
- X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state = 10)
- # Performing the logistic regression on train dataset
- log_reg.fit(X_train, Y_train)
- # Printing the accuracy score
- print(“Accuracy score of the predictions made by the model: “, accuracy_score(log_reg.predict(X_test), Y_test))

Машин сургалтын дэвшилтэт алгоритмууд Random Forest
- # Python program to show how to Random Forest Algorithm
- # importing the required libraries
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- from sklearn.ensemble import RandomForestClassifier
- # Loading the dataset
- X, Y = load_iris(return_X_y = True)
- # Segregating the dataset into training and testing dataset
- X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.4)
- # creating an object of the RF classifier class
- rf = RandomForestClassifier(n_estimators = 100)
- # Training the classifier model on the training dataset
- rf.fit(X_train, Y_train)
- # Predicting the values for the test dataset
- Y_pred = rf.predict(X_test)
- # using metrics module to calculate accuracy score
- print(“Accuracy score for the model is: “, accuracy_score(Y_test, Y_pred))
- # predicting the type of flower
- rf.predict([[5, 7, 3, 4]])