
Apache Spark бол их өгөгдөл боловсруулах, аналитик хийхэд зориулагдсан нээлттэй эхийн тархсан тооцоолох систем юм. Энэ нь өгөгдлийн параллелизм ба алдааг тэсвэрлэх чадвартай бүхэл кластеруудыг программчлах интерфейсээр хангадаг.
Apache Spark 3.5 нь Scala, Python, R болон Java хэл дээр ажилладаг фреймворк юм.
- Spark: Scala дээр суурилсан Spark-ийн үндсэн интерфэйс.
- PySpark: Python дээр суурилсан Spark-ийн интерфэйс.
- SparklyR: R програмчлалын хэл дээр суурилсан Spark-ийн интерфэйс.

Spark нь хурдан, уян хатан, хэрэглэхэд хялбар байхаар бүтээгдсэн тул их өгөгдлийн багц боловсруулахад түгээмэл сонголт болдог. Spark нь тархсан кластерууд дээр олон тэрбум, их наяд өгөгдөл дээр ажилладаг бөгөөд уламжлалт программуудаас 100 дахин хурдан ажилладаг.
Spark нь single-node машин эсвэл multi-node машин (Cluster) дээр ажиллах боломжтой. (Энэ нь MapReduce-ийн хязгаарлалтыг санах ойд боловсруулалт хийх замаар шийдвэрлэх зорилгоор бүтээгдсэн.)
Spark нь санах ойн кэш ашиглан өгөгдлийг дахин ашигладаг бөгөөд
нэг өгөгдлийн багц дээрх функцийг дахин дахин дууддаг машин сургалтыналгоритмуудыг хурдасгадаг.
(Энэ нь хоцролтыг багасгаж, Spark-ийг MapReduce-ээс хэд дахин хурдан болгодог, ялангуяа машин сургалт, интерактив аналитик хийх үед.)
Apache Spark нь мөн real-time streaming боловсруулах боломжтой.
Apache Spark-ийн гол онцлогуудад дараах зүйлс багтана:
Speed: Spark нь Hadoop MapReduce гэх мэт бусад том өгөгдөл боловсруулах хүрээтэй харьцуулахад санах ойн тооцоолол хийж, боловсруулалтын хурдыг ихээхэн нэмэгдүүлэх чадвартай тул хурдаараа алдартай.
Ease of Use: Spark нь Java, Scala, Python, R хэл дээр програмчлахад ашиглахад хялбар APIуудаар хангадаг бөгөөд энэ нь өөр өөр хэлний сонголттой хөгжүүлэгчдэд хүртээмжтэй болгодог.
Versatility– Олон талт байдал: Spark нь янз бүрийн даалгаварт зориулсан олон төрлийн сан, хэрэгслийг(tools) санал болгодог. Үүнд: SQL and structured data processing (Spark SQL), streaming data processing (Spark Streaming), machine learning (MLlib), and graph processing (GraphX).
Алдаанд тэсвэртэй байдал: Spark нь Resilient Distributed Datasets (RDD) ашиглан өгөгдлийн алдаанд тэсвэртэй байдлыг хангадаг. RDD нь өгөгдлийг олон удаа тооцоолох боломжийг олгодог бөгөөд энэ нь алдаа гарсан үед дахин тооцоолол хийх замаар алдаанаас сэргээх боломжийг олгодог.
Нэгтгэх чадвар: Spark нь Hadoop Distributed File System (HDFS), Amazon S3, Cassandra зэрэг олон төрлийн хадгалалтын системүүдтэй нэгтгэх боломжтой. Энэ нь өгөгдлийг янз бүрийн эх сурвалжаас авч боловсруулах, задлан шинжлэх боломжийг олгодог.

Apache Spark-ийн давуу талууд:
• Spark-ийг ашиглан Hadoop HDFS, AWS S3, Databricks DBFS, Azure Blob Storage зэрэг олон файлын системүүдээс өгөгдөл боловсруулах боломжтой.
• Spark мөн Streaming, Kafka зэрэг технологиудыг ашиглан бодит цагийн өгөгдлийг боловсруулах боломжтой.
• Spark Streaming-ийг ашиглан файлын систем, socket-ээс өгөгдөл урсгалыг авах боломжтой.
• Spark нь машин сургалт, графикийн сангуудыг өөртөө агуулдаг.
• MongoDB зэрэг NoSQL өгөгдлийн сангуудад өгөгдөл хадгалах холболтуудыг өгөх боломжтой.
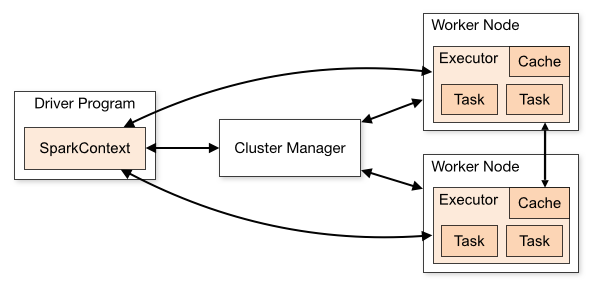
Apache Spark архитектур:
• Spark нь мастер-сүлжээний архитектурыг ашигладаг бөгөөд мастерыг “Driver” гэж нэрлэдэг бол сүлжээг “Worker” гэж нэрлэдэг.
Spark програмыг ажиллуулах үед Spark Driver нь таны програмын контекст болж, бүх үйлдлүүд нь Worker node дээр ажилладаг бөгөөд нөөцийг Cluster Manager-ээр дамжуулан удирддаг. Энэ архитектур нь том хэмжээний өгөгдлийг олон тооны машинаар тараан боловсруулах боломжийг олгодог бөгөөд ингэснээр өндөр гүйцэтгэлтэй, найдвартай боловсруулалтыг хангадаг.
Cluster Manager-ийн төрлүүд:
Spark нь дараах Cluster Manager дэмждэг:
• Standalone – Spark-тай хамт ирдэг энгийн кластер менежер бөгөөд кластерыг хялбархан тохируулах боломжийг олгодог.
• Apache Mesos – Mesos нь кластер менежер бөгөөд Hadoop MapReduce болон Spark програмуудыг ажиллуулах боломжтой.
• Hadoop YARN – Hadoop 2-ын нөөцийн менежер бөгөөд ихэвчлэн ашиглагддаг кластер менежер юм.
• Kubernetes – Containerized програмуудыг автоматаар ажиллуулах, хуваарилах, удирдах боломжийг олгодог нээлттэй эхийн систем юм.
local – Энэ нь жинхэнэ кластер менежер биш ч гэсэн би “local” гэдэг үгийг master()-д ашиглах ёстой, ингэснээр компьютер дээр Spark-ийг ажиллуулах боломжтой болно.
Хайлт
Категори
- 1 минутын уншлага
- 2 минутын уншлага
- AI
- Algorithm
- Bиртуалчлал
- Competitive programming
- computer science
- ide
- webiste
- Аюулгүй Байдал (4)
- боловсрол
- Зөвлөгөө
- Инженерчлэл ба Технологийн Системүүд (2)
- Код
- Компьютерын Шинжлэх Ухаан ба Програмчлал (1)
- Крипто
- Математик
- Өгөгдөл ба Хиймэл Оюун Ухаан (3)
- Программ хангамжийн төсөл
- Систем
- Сурагчдад
- Тархи ба Код
- Технологи, Нийгэм ба Боловсрол (5)
- Технологийн түүх
- Тоглоом хөгжүүлэлт
- Хөндлөнгийн
- Электроник


