FAIRSEQ: A Fast, Extensible Toolkit for Sequence Modeling
FAIRSEQ, by Facebook AI Research, and Google Brain
2019 NAACL, Over 1400 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, Machine Translation, Transformer
- FAIRSEQ-ийг санал танд болгож байна, энэ нь PyTorch-д суурилсан нээлттэй эхийн дарааллын загварчлалын хэрэгсэл бөгөөд судлаачид болон хөгжүүлэгчдэд орчуулга, нэгтгэн дүгнэх, хэлээр загварчлах болон бусад текст үүсгэх даалгаврын захиалгат загваруудыг сургах боломжийг олгодог.
- GitHub: https://github.com/pytorch/fairseq.
Outline
- FAIRSEQ Design
- FAIRSEQ Implementation
- Applications
1. FAIRSEQ дизайн
- Өргөтгөх боломж: FAIRSEQ-ийг хэрэглэгчээс нийлүүлсэн таван төрлийн залгаасуудаар өргөтгөх боломжтой бөгөөд энэ нь одоо байгаа бүрэлдэхүүн хэсгүүдийг аль болох дахин ашиглахын зэрэгцээ шинэ санааг туршиж үзэх боломжийг олгодог.
- Загварууд: Загварууд нь BaseFairseqModel классыг өргөтгөх ба энэ нь эргээд torch.nn.Module-ийг өргөтгөдөг.
- Шалгуур: Энэ нь загвар болон багц өгөгдлийн алдагдлыг тооцоолж болно, ойролцоогоор: алдагдал=шалгуур(загвар, багц), үүнийг шууд тооцоолох боломжтой.
- Даалгаварууд: толь бичгүүдийг хадгалах, өгөгдлийг ачаалах, багцлахад туслагчаар хангах, сургалтын давталтыг тодорхойлох.
- Оновчлогч: ихэнх PyTorch оновчтойлогчдын эргэн тойронд боодолтой болгох.
- Сургалтын хувь хэмжээг төлөвлөгч: хэд хэдэн алдартай хуваарь гарга.
- Дахин давтагдах, урагшлах нийцтэй байдал: Жишээлбэл, хяналтын цэгүүд нь загвар, оновчтой болгогч, өгөгдөл ачаалагчийн бүрэн төлөвийг агуулдаг. FAIRSEQ нь мөн урагшлах нийцтэй байдлыг хангадаг, тухайлбал, багаж хэрэгслийн хуучин хувилбаруудыг ашиглан бэлтгэгдсэн загварууд.
2. FAIRSEQ Implementation
2.1. Batching
- FAIRSEQ нь ижил урттай эх сурвалж болон зорилтот дарааллыг бүлэглэх замаар жижиг багц доторх дүүргэлтийг багасгадаг.
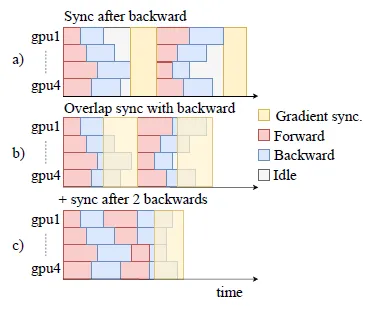
2.2. Олон GPU сургалт
- FAIRSEQ нь GPU хоорондын харилцаанд зориулж NCCL2 номын сан болон torch.distributed ашигладаг.
- (a): Олон GPU эсвэл олон машинтай тохиргоонд энэ нь ихэнх GPU-ийн сул зогсолтод хүргэдэг, харин удаашралтай ажилчид ажлаа дуусгадаг.
- (б): Давхардсан градиент синхрончлол нь сүлжээний хэсгүүдийн градиентийг тооцоолох үед тэдгээрийг синхрончилж эхэлдэг. Буферийн хэмжээ нь урьдчилан тодорхойлсон босгонд хүрэхэд градиентууд нь дэвсгэр урсгалд синхрончлогдоно, харин буцах тархалт ердийнхөөрөө үргэлжилнэ.
- (в): Градиентууд нь GPU бүр дээр олон дэд багцуудад хуримтлагддаг бөгөөд энэ нь дэд багц бүрийн дараа дампууруулагчдыг хүлээх шаардлагагүй тул ажилчдын хоорондын боловсруулалтын хугацааны зөрүүг багасгадаг.
2.3. Mixed Precision
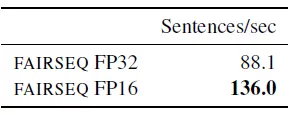
All forward-backward computations түүнчлэн ажилчдын хоорондох градиент синхрончлолын бүх бууралтыг FP16-д гүйцэтгэв. Гэсэн хэдий ч параметрийн шинэчлэлтүүд FP32-д хэвээр байна.
Translation speed measured on a V100 GPU on the test set of the standard WMT’14 English-German benchmark using a big Transformer model
2.4. Inference
- FAIRSEQ нь өсөн нэмэгдэж буй декодчилох замаар давтагдахгүй загваруудад хурдан дүгнэлт өгдөг бөгөөд өмнө нь үүсгэгдсэн жетонуудын загварын төлөвийг идэвхтэй цацраг бүрт кэш болгож, дахин ашигладаг.
- FAIRSEQ нь FP16-д гарсан дүгнэлтийг дэмждэг бөгөөд энэ нь дээр үзүүлсэн шиг тайлах хурдыг FP32-той харьцуулахад нарийвчлалын алдагдалгүйгээр 54%-иар нэмэгдүүлдэг.
3. Applications
3.1. Machine Translation
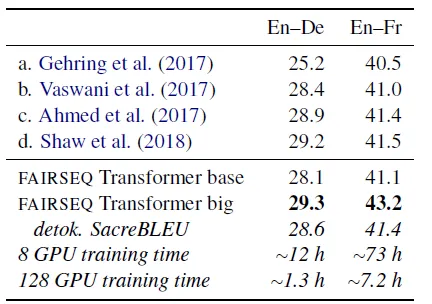
BLEU on news2014 for WMT English-German (En–De) and English-French (En–Fr)
- Трансформаторын кодлогч-декодерын “том” загварыг WMT англи хэлнээс герман (En–De) болон WMT англи хэлнээс франц хэл (En–Fr) гэсэн хоёр хэлний хосоор үнэлдэг. Бүх үр дүн нь цацрагийн өргөн нь 4, уртын торгууль нь 0.6-тай цацрагийн хайлтыг ашигладаг.
FAIRSEQ нь илүү том багцын хэмжээтэй, сургалтын хурдыг нэмэгдүүлснээр анхны Трансформатортой харьцуулахад BLEU оноог сайжруулдаг.
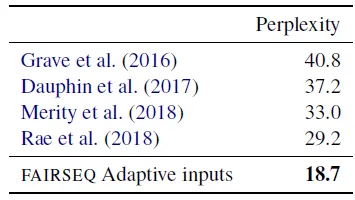
Test perplexity on WikiText-103
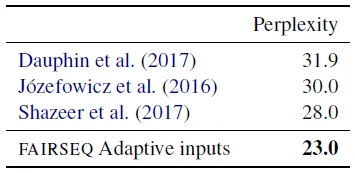
Test perplexity on the One Billion Word benchmark
- Baevski and Auli (2019) хоёрын дараа зөвхөн декодчилогч сүлжээ болон дасан зохицох оролтын суулгацыг ашигладаг Трансформатор хэлний хоёр загварыг үнэлэв.
- Эхний загвар нь 16 блоктой, дотоод хэмжээ нь 4К, суулгацын хэмжээ 1К; WikiText-103 дээрх үр дүн.
- Хоёрдахь загвар нь 24 блоктой, дотоод хэмжээ нь 8К, оруулах хэмжээ нь 1.5К; Нэг тэрбум үгийн жишиг үнэлгээний үр дүн.
3.3. Abstractive Document Summarization
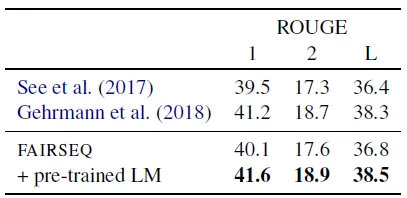
Abstractive summarization results on the full-text version of CNN-DailyMail dataset
Оролтын баримтыг кодлож, дараа нь декодчилогч сүлжээгээр хураангуйг үүсгэдэг үндсэн трансформаторыг CNN-Dailymail мэдээллийн багц дээр үнэлдэг.
Reference
[2019 NAACL] [FAIRSEQ]
FAIRSEQ: A Fast, Extensible Toolkit for Sequence Modeling