
Бүх нийтлэлүүд
2026.06.163 min read#хиймэлоюунбаөгөгдлийншинжлэхухаан#AI , MFCC
Дуу авиаг хэрхэн зураг болгон хувиргадаг вэ? MFCC-ийн ард нуугдсан технологи
Г.Хишигжаргал
Багш
Г.Хишигжаргал
Багш
Бид өдөр бүр дуут мессеж илгээж, дуу хоолойгоороо хайлт хийж, хиймэл оюунтай ярилцдаг. Хүн хэдхэн секунд сонсоод л найзынхаа хоолойг таньж чадна. Харин компьютер бидэн шиг “сонсдоггүй”. Компьютерийн хувьд дуу хоолой гэдэг нь маш олон тоон утгаас бүрдсэн долгион юм.
Тэгвэл хиймэл оюун эдгээр тоонуудыг хэрхэн ойлгож, хүний яриа, дуу хоолой, авиа зэргийг таньдаг вэ? Үүний ард MFCC буюу Mel-Frequency Cepstral Coefficients гэх чухал арга ажилладаг.
MFCC буюу Mel-Frequency Cepstral Coefficients нь аудио өгөгдлөөс хамгийн чухал шинж чанаруудыг ялган авч, компьютерт ойлгомжтой хэлбэрт хөрвүүлдэг арга юм. Энгийнээр хэлбэл, урт бөгөөд төвөгтэй дуу авиаг илүү цэгцтэй, жижиг мэдээллийн багц болгон хувиргадаг гэсэн үг. Энэ нь компьютерт бүх дууг нэг бүрчлэн боловсруулахын оронд хамгийн хэрэгтэй хэсгийг нь үлдээх боломж олгодог. Яг л урт номын гол санааг товчлон тэмдэглэж авч байгаатай адил юм.
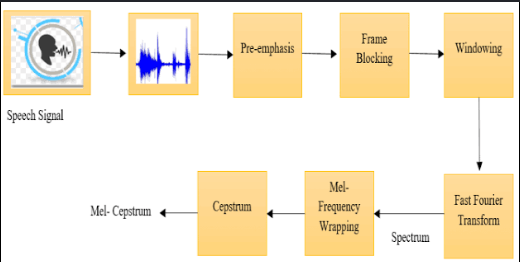
Хүн дууг чихээрээ сонсдог бол компьютер тоон өгөгдөл хэлбэрээр хүлээн авдаг. Жишээлбэл, 5 секундын аудио хэдэн арван мянган жижиг тоон утгаас бүрдэж болно. Гэхдээ энэ хэмжээний мэдээллийг шууд боловсруулна гэдэг маш хэцүү. Тиймээс эхлээд дууг маш богино хэсгүүдэд хуваадаг. Ихэвчлэн 20-40 миллисекунд үргэлжлэх жижиг хэсгүүд болгон задлаад тус бүрийг нь тусад нь шинжилдэг.
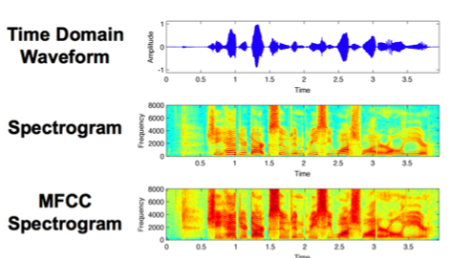
Энэ үйл явц хэд хэдэн алхамтай. Эхлээд аудиог жижиг хэсгүүдэд хувааж, дараа нь тухайн хэсэг бүрийн давтамжийг тооцоолдог. Үүний дараа хүний сонсголд ойр байдлаар Mel scale ашиглан мэдээллийг дахин боловсруулна. Эцэст нь хамгийн чухал шинжүүдийг ялгаж авснаар хоёр хэмжээст хүснэгт шиг бүтэц үүсдэг. Нэг тэнхлэг нь хугацаа, нөгөө нь дууны онцлог шинжүүдийг илэрхийлдэг бөгөөд энэ нь жижиг зураг эсвэл дулааны зураг (heatmap) шиг харагддаг.
Хиймэл оюун зураг боловсруулахдаа маш сайн байдаг. Харин түүхий аудио өгөгдөл нь хэт урт, төвөгтэй байдаг тул боловсруулахад хүндрэлтэй. MFCC нь энэ асуудлыг шийдэж, аудиог илүү цэгцтэй бүтэцтэй болгодог. Ингэснээр машин сургалтын загварууд дуу хоолойн хэв маягийг илүү хурдан сурч чаддаг. Ялангуяа Deep Learning загварууд ийм төрлийн дүрслэл дээр маш сайн ажилладаг.
MFCC нь бидний өдөр тутам ашигладаг олон технологийн ард ажиллаж байдаг. Дуут туслахууд, яриа таних системүүд, дуучныг таних системүүд, дуут команд бүхий аппликейшнүүд бүгд энэ аргыг ашиглаж болно. Мөн сэтгэл хөдлөл илрүүлэх, хэл таних, аюулгүй байдлын биометрийн системүүдэд ч өргөн хэрэглэгддэг. Бид анзаарахгүй байж болох ч, энэ технологи өдөр бүр хэдэн сая хүний төхөөрөмж дээр ажиллаж байдаг.
Компьютер хүн шиг сонсож чаддаггүй ч дуу авиаг өөрийн ойлгодог хэл рүү хөрвүүлж чаддаг. MFCC нь энэ хөрвүүлэлтийг хийх хамгийн өргөн хэрэглэгддэг аргуудын нэг юм. Энэ технологи аудиог энгийн тоон дарааллаас илүү ойлгомжтой хоёр хэмжээст дүрслэл болгон хувиргадаг. Өөрөөр хэлбэл, MFCC нь хиймэл оюунд дуу хоолойг “сонсох” биш, харин “харах” боломжийг олгодог технологи юм.