Олон улсын хэмжээнд үүнийг компьютер, мэдээллийн технологийн салбарт "Өгөгдлийн сангаас мэдлэг илрүүлэх" (Knowledge Discovery in Databases буюу KDD) үйл явцын хамгийн гол, шийдвэрлэх үе шат гэж үздэг.
Олон нийтийн дунд "Өгөгдөл олборлолт" болон "Өгөгдлийн сангаас мэдлэг илрүүлэх" (KDD) гэсэн нэр томьёог ижил утгаар хэрэглэх хандлага байдаг ч, академик түвшинд Өгөгдөл олборлолт нь KDD үйл явцын ердөө нэг шийдвэрлэх үе шат нь юм (Fayyad et al., 1996).
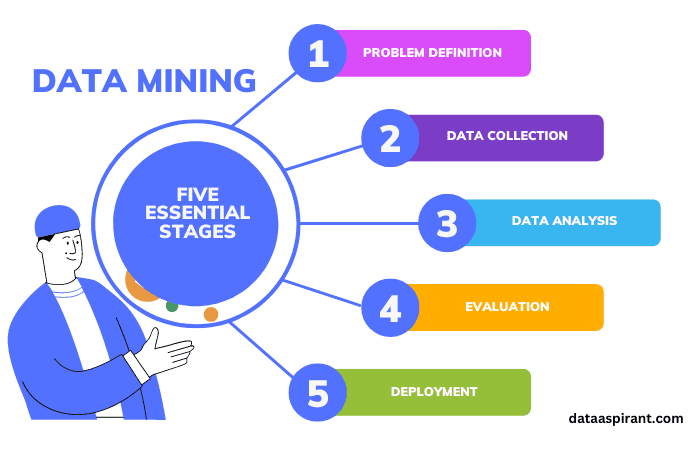
Бүрэн хэмжээний KDD үйл явц нь дараах 5 үндсэн үе шатаас бүрдэнэ:
Өгөгдлийг сонгох (Data Selection): Судалгааны зорилгод нийцэх, дүн шинжилгээ хийхэд шаардлагатай өгөгдлийн олонлогийг зорилтот өгөгдлийн сангаас тусгаарлан авах.
Өгөгдлийг урьдчилан боловсруулах (Data Preprocessing): Энэ шатанд өгөгдлийн шуугианыг (noise) арилгах, дутуу утгуудыг нөхөх, алдаатай бичлэгүүдийг цэвэрлэх стратегиудыг хэрэглэнэ.
Өгөгдлийг хувиргах (Data Transformation): Өгөгдлийг олборлолтын алгоритмд шинжүүлэхэд бэлэн хэлбэрт оруулах (нэгтгэх, хэмжээсийг багасгах, нормалчлах үйл явц).
Өгөгдөл олборлолт (Data Mining): KDD-ийн хамгийн чухал үе шат. Энэ шатанд бэлэн болсон өгөгдөл дээр математик болон машин сургалтын алгоритмуудыг ажиллуулж, далд байгаа хэв маягийг (patterns) эрж хайна.
Үр дүнг үнэлэх, тайлбарлах (Evaluation & Interpretation): Илэрсэн хэв маягуудыг шинжлэх ухааны болон бизнесийн үүднээс үнэлж, жинхэнэ "Мэдлэг" (Knowledge) болгон хувиргах.

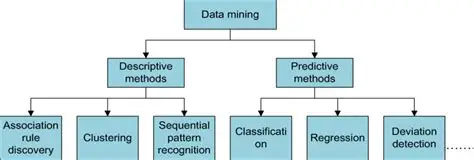
Өгөгдөл олборлолтыг албан ёсны судалгаанд дараах үндсэн хоёр зорилгод хувааж, алгоритмуудыг ашигладаг:
Эдгээр аргууд нь одоо байгаа өгөгдөл дээр тулгуурлан ирээдүйд үүсэж болох үр дүнг таамаглахад чиглэдэг.
А. Ангилал ба Таамаглал (Classification & Prediction)
Өгөгдлийн түүвэр тус бүрийг урьдчилан бэлдсэн шошго (label) буюу ангилалд хуваарилах хяналттай сургалтын (Supervised Learning) арга юм.
Шийдвэрийн мод (Decision Trees): Өгөгдлийг тодорхой нөхцөлүүдээр салбарлуулан мод хэлбэрийн бүтэц үүсгэж шийдвэр гаргадаг. (Жишээ алгоритм: ID3, C4.5, CART)
Тулгуур векторын машин (Support Vector Machines - SVM): Өгөгдлийн ангиудыг хооронд нь тусгаарлах хамгийн оновчтой заагийг (Hyperplane) математик аргаар олдог алгоритм. Хэмжээс ихтэй өгөгдөлд маш үр дүнтэй.
Нейрон сүлжээ (Neural Networks): Хүний тархины ажиллагаанаас сэдэвлэсэн, оролт ба гаралтын хоорондох шугаман бус, маш нарийн хамаарлыг илрүүлдэг гүн сургалтын (Deep Learning) үндэс суурь.
2.Дүрслэн харуулах үүрэгтэй аргууд (Descriptive Methods)
Өгөгдлийн ерөнхий шинж чанар, дотоод бүтцийг нээж илрүүлэхэд чиглэдэг.
Урьдчилан тодорхойлсон шошго байхгүй үед өгөгдлийг өөрийнх нь дотоод ижил төстэй шинж чанарт үндэслэн бүлэглэх хяналтгүй сургалтын (Unsupervised Learning) арга юм.
K-Means алгоритм: Өгөгдлийг урьдчилан сонгосон $K$ тооны бүлэгт (бөөгнөрөлд) хуваах бөгөөд бөөгнөрөл тус бүрийн төв цэгээс (Centroid) бусад өгөгдөл хүртэлх зайг (Евклидийн зай) хамгийн бага байхаар тооцдог.
Иерархи бөөгнөрөл (Hierarchical Clustering): Өгөгдлийг мод хэлбэрийн шатлалтай бүтэц (Dendrogram) үүсгэн дээрээс доош эсвэл доороос дээш чиглэлээр бүлэглэх арга.
Том хэмжээний гүйлгээний өгөгдлийн сангаас хувьсагчдын хоорондын сонирхолтой хамаарал, хамтын холбоог илрүүлэх арга (Tan, Steinbach, & Kumar, 2018).
Apriori алгоритм: Түгээмэл худалдан авагддаг бүтээгдэхүүний багцыг олоход ашиглагддаг суурь алгоритм. Үүнд хоёр гол хэмжигдэхүүн байдаг:
Дэмжлэг (Support): Тухайн бүтээгдэхүүний хослол нийт гүйлгээний хэдэн хувьд нь хамт харагдаж байгааг илэрхийлнэ.
Итгэлцүүр (Confidence): $A$ бүтээгдэхүүнийг авсан хэрэглэгч $B$ бүтээгдэхүүнийг худалдаж авах магадлалын хув
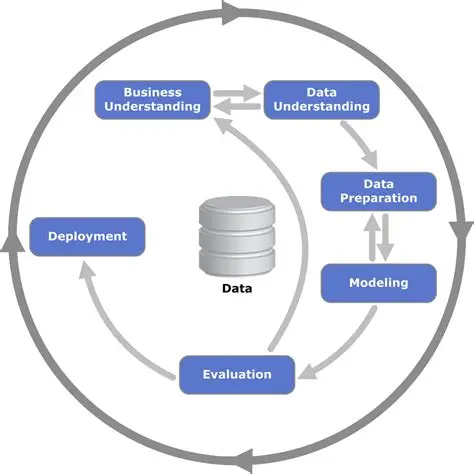
Өгөгдөл олборлолтын төслийг хэрэгжүүлэхдээ дэлхий даяар CRISP-DM (Cross-Industry Standard Process for Data Mining) хэмээх стандартыг мөрддөг. Үүнд 6 үе шат багтана:
Business Understanding: Төслийн зорилго болон бизнесийн шаардлагыг тодорхойлох.
Data Understanding: Анхны өгөгдлийг цуглуулах, чанарыг нь үнэлэх, эхний ойлголтыг авах.
Data Preparation: Түүхий өгөгдлийг цэвэрлэх, форматлах, загварчлалд бэлдэх үе шат (Хамгийн их цаг авдаг).
Modeling: Өгөгдөл олборлолтын алгоритмуудыг сонгон ажиллуулж, загвар үүсгэх.
Evaluation: Гарсан үр дүн нь бизнесийн зорилгод нийцэж байгаа эсэхийг үнэлэх.
Deployment: Гаргаж авсан мэдлэг, загварыг практикт нэвтрүүлж, шийдвэр гаргалтад ашиглах.
Han, J., Kamber, M., & Pei, J. (2011). Data Mining: Concepts and Techniques. Morgan Kaufmann. (Энэ бол дэлхийн их дээд сургуулиудад ашиглагддаг өгөгдөл олборлолтын "Библи" гэгддэг гол сурах бичиг юм).
Tan, P. N., Steinbach, M., & Kumar, V. (2018). Introduction to Data Mining. Pearson. (Статистик болон алгоритмын үндсийг маш тодорхой тайлбарласан эх сурвалж).
Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). From Data Mining to Knowledge Discovery in Databases. AI Magazine. (Өгөгдөл олборлолтын шинжлэх ухааны анхны албан ёсны тодорхойлолтуудыг гаргасан суурь судалгааны бүтээл).
Witten, I. H., Frank, E., Hall, M. A., & Pal, C. J. (2016). Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann. (Машин сургалтын практик хэрэглээ талыг түлхүү харуулсан бүтээл).
