
Бүх нийтлэлүүд
2026.05.154 min read#хиймэлоюунбаөгөгдлийншинжлэхухаан#Mixture of Experts#LLM#Transformer#Deep Learning
Mixture of Experts (MoE) гэж юу вэ?
З.Номин-Эрдэнэ
Багш
З.Номин-Эрдэнэ
Багш
Сүүлийн жилүүдэд хиймэл оюун ухааны хөгжил асар хурдтай өсөж, GPT, Claude, Gemini, Mixtral зэрэг том хэлний загварууд (LLM) хүнтэй төстэй түвшинд текст ойлгож, код бичиж, асуудал шийдвэрлэх чадвартай болсон. Гэвч эдгээр системүүдийн хамгийн том асуудал нь асар их хэмжээний параметр болон тооцооллын зардал юм.
Жишээлбэл, хэдэн зуун тэрбум параметртэй загварыг ажиллуулахын тулд маш өндөр хүчин чадалтай GPU кластер шаардлагатай болдог. Ийм үед “илүү том загвар бүтээх” биш, харин “илүү ухаалаг ажиллуулах” шинэ арга хэрэгтэй болсон. Энэ асуудлын шийдлийн нэг нь Mixture of Experts (MoE) архитектур юм.
MoE нь нэг том нейрон сүлжээний оронд олон жижиг “expert” нейрон сүлжээг хамтад нь ашигладаг архитектур бөгөөд зөвхөн шаардлагатай хэсгийг идэвхжүүлдэгээрээ онцлогтой. Өөрөөр хэлбэл, бүх системийг зэрэг ажиллуулахын оронд тухайн даалгаварт хамгийн тохиромжтой expert-үүдийг л сонгон ажиллуулдаг.
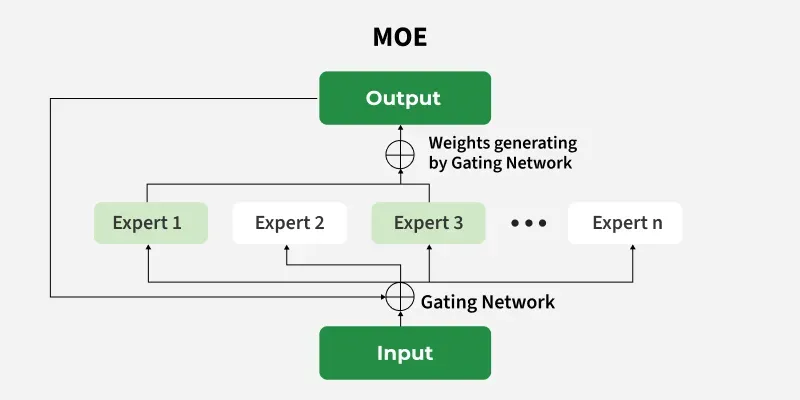
MoE архитектур нь гурван гол хэсгээс бүрддэг.
MoE-ийг ойлгохын тулд энгийн нэг жишээ авч үзвэл :
Хэрэв нэг эмнэлэгт бүх өвчтөнийг ганц эмч үздэг бол тэр эмч бүх төрлийн өвчнийг мэдэх шаардлагатай болно. Харин бодит амьдрал дээр:
зүрхний эмч
мэдрэлийн эмч
нүдний эмч,
мэс засалч
гэж тус тусдаа мэргэжилтнүүд байдаг.
MoE архитектур яг үүнтэй ижил зарчмаар ажилладаг.
Experts нь тус тусдаа мэргэшсэн жижиг neural network буюу өөр өөр төрлийн мэдээлэл дээр илүү сайн ажиллах зориулалттай жижиг нейрон сүлжээнүүд юм. Нэг expert нь хэлний бүтэц боловсруулахад сайн байхад, нөгөө нь дүрсийн онцлог танихад илүү тохиромжтой байж болно.
Gate нь оролтын мэдээллийг шинжилж, аль expert-үүд рүү илгээхийг шийддэг хэсэг юм. Өөрөөр хэлбэл gate нь “энэ өгөгдөлд аль мэргэжилтэн илүү тохирох вэ?” гэж шийдвэр гаргадаг.
Сонгогдсон expert-үүдийн гаралтыг нэгтгэж, эцсийн хариуг гаргана. Ингэснээр систем бүх параметрийг зэрэг ашиглахгүй мөртлөө асар том хүчин чадалтай ажиллаж чаддаг.
MoE-ийн хамгийн чухал онцлог бол Sparse Activation буюу сийрэг идэвхжил юм. Энэ нь системийн бүх expert-үүдийг зэрэг ажиллуулахгүй, зөвхөн хэрэгтэй хэсгийг сонгон идэвхжүүлдэг гэсэн үг.

Жишээлбэл, дээрх зурагт “What is 1 + 1?” гэсэн оролт орж ирэхэд gate механизм тухайн асуултыг тоон мэдээлэлтэй холбоотой гэж тодорхойлж, зөвхөн Numbers expert-ийг идэвхжүүлж байна. Харин punctuation, verbs, conjunctions зэрэг бусад expert-үүд ажиллахгүй үлдэж байна.
Энэ нь MoE архитектурын хамгийн чухал онцлог болох Sparse Activation-ийг харуулж байгаа юм. Үүний үр дүнд:
GPU ачаалал буурна
Санах ойн хэрэглээ багасна
Inference хурд нэмэгдэнэ
Тооцооллын зардал буурна
Ингэснээр MoE архитектур нь асар том параметртэй загваруудыг илүү үр ашигтайгаар ажиллуулах боломжийг бүрдүүлдэг.
MoE архитектурын хамгийн чухал хэсэг бол gate буюу routing механизм юм. Gate буруу expert сонговол загварын чанар муудах магадлалтай. Тиймээс routing механизм нь оролтын мэдээллийг маш зөв ангилж, тохирох expert-үүдийг сонгох шаардлагатай байдаг.
Орчин үеийн MoE системүүд ихэвчлэн Top-k Routing ашигладаг. Энэ арга нь хамгийн өндөр үнэлгээтэй k expert-ийг сонгон идэвхжүүлдэг.
MoE архитектурын хамгийн төвөгтэй асуудлуудын нэг нь load balancing буюу ачааллын тэнцвэржилт юм. Зарим expert хэт олон удаа сонгогдож, зарим нь бараг ашиглагдахгүй байх тохиолдол гардаг.
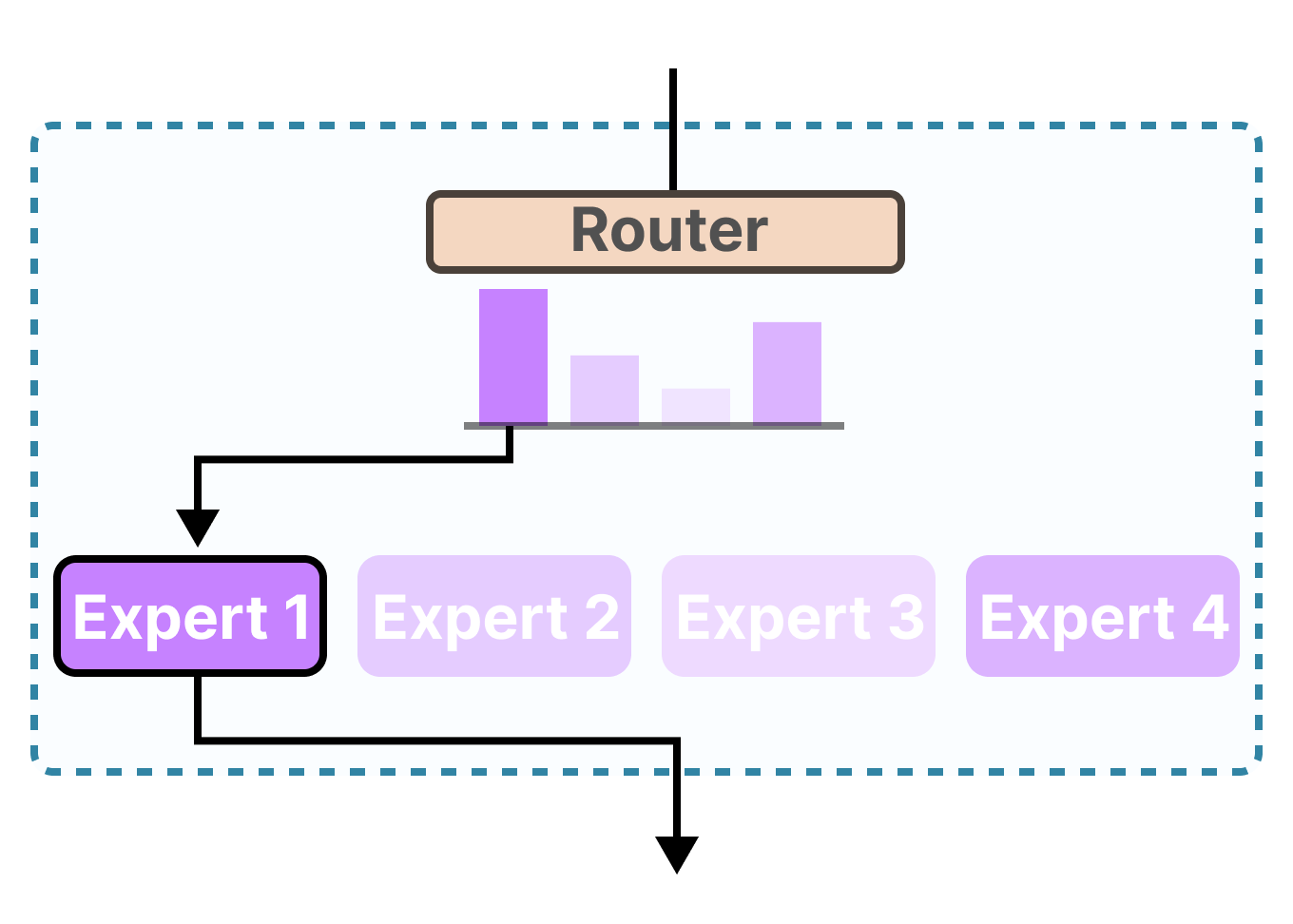
Дээрх зурагт router механизм оролтыг expert-үүд рүү хэрхэн хуваарилж байгааг харуулж байна. Энэ тохиолдолд router ихэвчлэн Expert 1-ийг сонгон идэвхжүүлж байгаа бөгөөд бусад expert-үүд харьцангуй бага ашиглагдаж байна. Ийм байдал удаан үргэлжилбэл load balancing буюу ачааллын тэнцвэржилтийн асуудал үүсдэг. Өөрөөр хэлбэл:
зарим expert хэт их ачаалалтай болно,
бусад expert хангалттай ашиглагдахгүй үлдэнэ,
сургалт тэнцвэргүй явагдана,
expert specialization муудах эрсдэлтэй болно.
Жишээлбэл, зураг дээр Expert 1 байнга сонгогдож байвал Expert 2, Expert 3, Expert 4 нь бараг суралцахгүй үлдэж болно. Үүний үр дүнд системийн нийт гүйцэтгэл буурч, MoE архитектурын давуу тал алдагдах магадлалтай. Энэ асуудлыг шийдэхийн тулд MoE системүүд:
auxiliary loss,
routing penalty,
balancing constraint
зэрэг аргуудыг ашиглан router-ийг expert-үүдийг илүү тэнцвэртэй ашиглахад чиглүүлдэг. Ингэснээр бүх expert ойролцоо хэмжээгээр суралцаж, систем илүү тогтвортой ажиллах боломж бүрддэг.
Доорх жишээ нь HuggingFace Transformers ашиглан Mixtral 8x7B MoE загварыг хэрхэн дуудахыг харуулж байна.
Тооцооллын үр ашиг өндөр : Бүх параметрийг зэрэг ажиллуулахгүй тул compute cost болон GPU ачаалал багасдаг.
Том хэмжээний загвар байгуулах боломж: Sparse activation ашигласнаар хэдэн их наяд параметртэй загвар байгуулах боломжтой.
Expert Specialization: Experts нь тодорхой төрлийн өгөгдөл дээр мэргэшиж, илүү сайн гүйцэтгэл үзүүлдэг.
Scalability: Distributed system орчинд илүү сайн өргөжиж, parallel computation хийх боломжтой.
Routing механизм төвөгтэй: Gate буруу expert сонговол загварын чанар мууддаг.
Load Balancing асуудал: Зарим expert хэт ачаалалтай болж, зарим нь ашиглагдахгүй үлдэх эрсдэлтэй.